Comment toxicity Prediction using Deep learning
This is my project on comment toxicity prediction using Deep learning and TensorFlow. This is one of my favorite project because it includes neural networks and the Tensorflow framework moreover, I got this challenge from Kaggle. I have built many projects related to healthcare, and computer vision and so on but this project surprised me because comments are everywhere from websites to social media.
Background on the problem statement
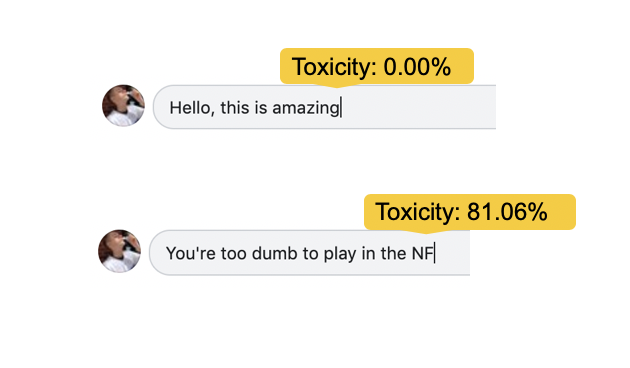
The problem statement originates from massive online forums where people post comments about the product. Comments are sometimes Abusive, insulting or even hate based, so it has become the responsibility of the hosting organizations to ensure that the conversations are positive but not negative type. The need to identify and remove the negativity from the comments is to eliminate disrespectful, or unreasonable content that is likely to make people leave a discussion. Many forms of toxicity are obvious, including racism, hate speech, harassment, profane language, and threats
Approach to the problem statement
Dataset is publicly on Kaggle over here. The dataset has no null values and it is perfectly available for training the Deep neural network.
• Loading the data
The project was completely executed in the google collaboratory. The first step is to load the Dataset
in the google colab which is available from the link in the above section
we can make use of open-source libraries like pandas to convert the dataset into the form of a data
frame which is highly recommended for any machine learning project.
• Preprocessing comments
Before providing the inputs to the Deep learning model we have to preprocess the comments present in the
data frame. we can convert the comments into tokens where every word has a unique identifier
this process is called tokenizer. In simple words, tokenization is the process of tokenizing or
splitting a string or text into a list of tokens. After tokenization, we convert them into embeddings
where it represents certain attributes about a token or a text.
• Creating a Deep Natural Language Processing model
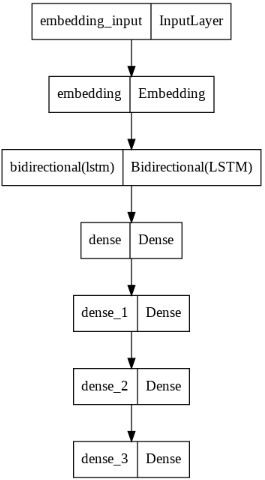
The above picture is a graphical representation of the deep learning model used in the project. it consists of several layers including Embedding layers, Bidirectional LSTM(long short-term memory) layers and Dense layers. An LSTM layer above provides a sequence output. Specifically, one output per input time step, rather than one output time step for all input time steps.
• Evaluating the model
The model takes a lot of time to train because it has around 6 million parameters to train. It was
trained for 5 epochs and it is evaluated on the dev set.
it has got Precision:0.900296151638031, Recall:0.7646729946136475, Accuracy:0.5185556411743164. In the
future I will improve the model by collecting more data and
training for longer duration.
• Conclusion
Hence this was the breakthrough of my project on comment toxicity prediction using Deep learning and
Tensorflow.